

MySQL面试题
本文最后更新于 2026-05-18,文章内容可能已经过时。
mysql中的一些基本函数,你知道哪些?
1.字符串函数
CONCAT(str1, str2, ...): 连接多个字符串,返回一个合并后的字符串。
SELECT CONCAT('Hello', ' ', 'World') AS Greeting;LENGTH(str): 返回字符串的长度(字符数)。
SELECT LENGTH('Hello') AS StringLength;SUBSTRING(str, pos, len): 从指定位置开始,截取指定长度的子字符串。
SELECT SUBSTRING('Hello World', 1, 5) AS SubStr;REPLACE(str, from_str, to_str): 将字符串中的某部分替换为另一个字符串。
SELECT REPLACE('Hello World', 'World', 'MySQL') AS ReplacedStr;2.数值函数
ABS(num): 返回数字的绝对值。
SELECT ABS(-10) AS AbsoluteValue;POWER(num, exponent): 返回指定数字的指定幂次方。
SELECT POWER(2, 3) AS PowerValue;三、日期和时间函数
NOW():返回当前日期和时间。
SELECT NOW() AS CurrentDateTime;CURDATE():返回当前日期。
SELECT CURDATE() AS CurrentDate;4.聚合函数
COUNT(column):计算指定列中的非NULL值的个数。
SELECT COUNT(*) AS RowCount FROM my_table;SUM(column):计算指定列的总和。
SELECT SUM(price) AS TotalPrice FROM orders;AVG(column):计算指定列的平均值。
SELECT AVG(price) AS AveragePrice FROM orders;MAX(column):返回指定列的最大值。
SELECT MAX(price) AS MaxPrice FROM orders;MIN(column):返回指定列的最小值。
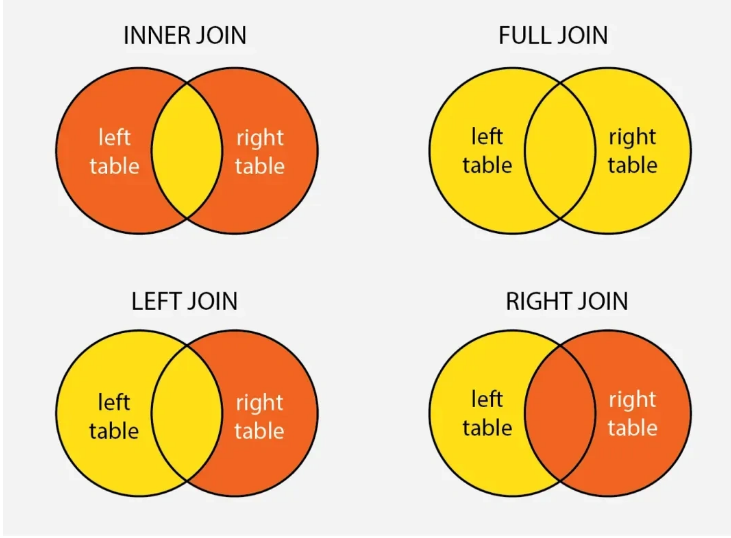
SELECT MIN(price) AS MinPrice FROM orders;MySQL 怎么连表查询?
CHAR 和 VARCHAR有什么区别?
CHAR是固定长度的字符串类型,定义时需要指定固定长度,存储时会在末尾补足空格。CHAR适合存储长度固定的数据,如固定长度的代码、状态等,存储空间固定,对于短字符串效率较高。
VARCHAR是可变长度的字符串类型,定义时需要指定最大长度,实际存储时根据实际长度占用存储空间。VARCHAR适合存储长度可变的数据,如用户输入的文本、备注等,节约存储空间。
MySQL的关键字in和exist
IN 用于检查左边的表达式是否存在于右边的列表或子查询的结果集中。如果存在,则IN 返回TRUE,否则返回FALSE
SELECT column_name(s)
FROM table_name
WHERE column_name IN (value1, value2, ...);EXISTS 用于判断子查询是否至少能返回一行数据。它不关心子查询返回什么数据,只关心是否有结果。如果子查询有结果,则EXISTS 返回TRUE,否则返回FALSE。
SELECT column_name(s)
FROM table_name
WHERE EXISTS (SELECT column_name FROM another_table WHERE condition);如何定位慢查询?
我们当时做压测的时候有的接口非常的慢,接口的响应时间超过了2秒以上(介绍一下当时产生问题的场景)
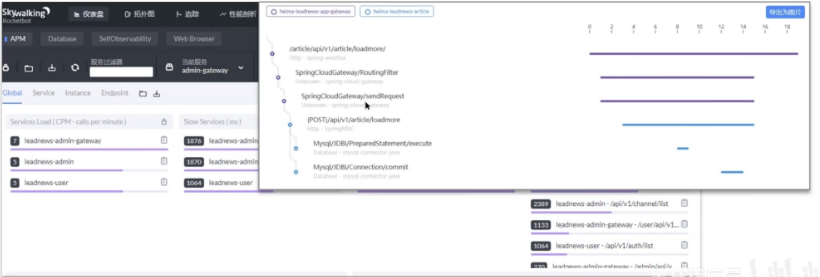
因为我们当时的系统部署了运维的监控系统 Skywalking,在展示的报表中可以看到是哪一个接口比较慢,并且可以分析这个接口哪部分比较慢,这里可以看到SQL的具体的执行时间,所以可以定位是哪个sql出了问题
如果,项目中没有这种运维的监控系统,其实在MySQL中也提供了慢日志查询的功能,可以在MySQL的系统配置文件中开启这个慢日志的功能,并且也可以设置SQL执行超过多少时间来记录到一个日志文件中,我记得上一个项目配置的是2秒,只要SQL执行的时间超过了2秒就会记录到日志文件中,我们就可以在日志文件找到执行比较慢的SQL了。(调试阶段)
方案一:开源工具
调试工具:Arthas 运维工具:Prometheus、Skywalking
方案二:MySQL自带慢日志
慢日志记录了所有执行时间超过指定参数 (long query time,单位:秒,默认10秒)的所有SQL语句的日志
# 如果要开启慢查询日志,需要在MySQL的配置文件 (/etc/my. cnf)中配置如下信息:
# 开启MySQL慢日志查询开关
slow query log=1
# 设置慢日志的时间为2秒,SQL语句执行时间超过2秒,就会视为慢查询,记录慢查询日志
long query time=2配置完毕之后,通过以下指令重新启动MySQL服务器进行测试,查看慢日志文件中记录的信息/ var/ lib/ mysql/ localhost-slow. log

一个SQL语句执行很慢,如何分析
如果一条sql执行很慢的话,我们通常会使用mysql自带的分析工具explain来去查看这条sql的执行情况。比如在这里面可以通过key和key_len检查是否命中了索引,如果本身已经添加了索引,也可以判断索引是否有失效的情况;第二个,可以通过type字段查看sql是否有进一步的优化空间,是否存在全索引扫描或全盘扫描;第三个可以通过extra建议来判断,是否出现了回表的情况,如果出现了,可以尝试添加索引或修改返回字段来修复。

possible_key 当前sql可能会使用到的索引
key 当前sql实际命中的索引
key_len 索引占用的大小
type 这条sql的连接的类型,性能由好到差为NULL、system、const、eq ref、ref、range、index、all
system:查询系统中的表
const:根据主键查询
eq ref:主键索引查询或唯一索引查询
ref:索引查询
range: 范围查询
index: 索引树扫描
all:全盘扫描
Extra 额外的优化建议
了解过索引吗?(什么是索引)
索引类似于书籍的目录,它是帮助MySQL高效获取数据的数据结构,主要是用来提高数据检索的效率,降低数据库的IO成本,同时通过索引列对数据进行排序,降低数据排序的成本,也能降低了CPU的消耗
索引的底层数据结构了解过吗?
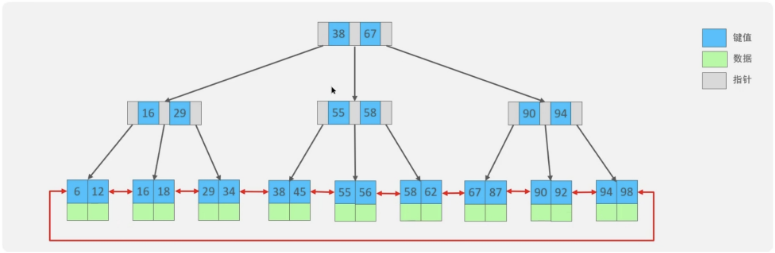
MySQL的默认的存储引擎InnoDB采用的B+树的数据结构来存储索引,选择B+树的主要的原因是:第一阶数更多,路径更短,第二个B+树的磁盘读写代价更低,非叶子节点只存储指针,叶子节点存储数据,第三是B+树便于扫库和区间查询,叶子节点是一个双向链表
B树和B+树的区别是什么呢?
第一:在B树中,非叶子节点和叶子节点都会存放数据,而B+树的所有的数据都会出现在叶子节点,而非叶子节点只存储索引信息,在查询的时候,B+树查找效率更加稳定
第二:在进行范围查询的时候,B+树效率更高,因为B+树都在叶子节点存储,并且叶子节点是一个双向链表,这样的好处是既能向右遍历,也能向左遍历。
B树与B+树对比:
①:磁盘读写代价B+树更低;②:查询效率B+树更加稳定;③:B+树便于扫库和区间查询
数据结构对比
B-Tree,B树是一种多叉路衡查找树,相对于二叉树,B树每个节点可以有多个分支,即多叉。以一颗最大度数 (max-degree) 为5(5阶)的b-tree为例,那这个B树每个节点最多存储4个key
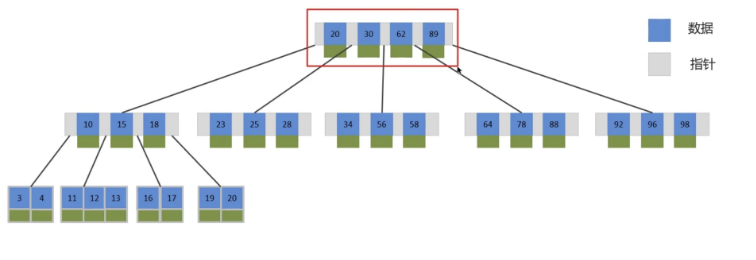
B+Tree是在BTree基础上的一种优化,使其更适合实现外存储索引结构,InnoDB存储引擎就是用B+Tree实现其索引结构
什么是聚簇索引什么是非聚簇索引?
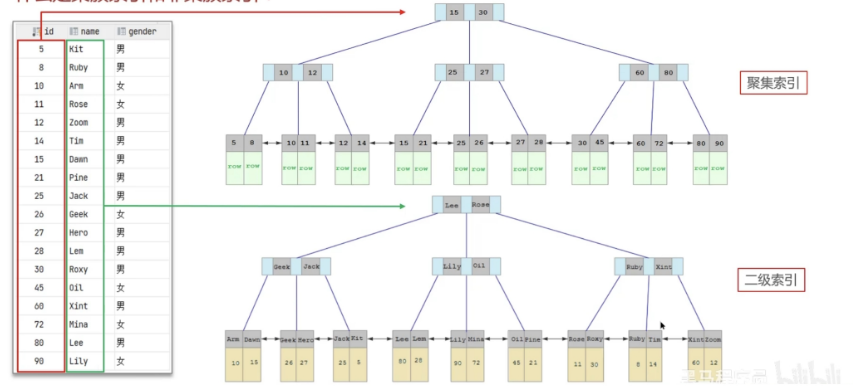
聚簇索引主要是指数据与索引放到一块,B+树的叶子节点保存了整行数据,有且只有一个,一般情况下主键在作为聚族索引的
聚集索引选取规则:
如果存在主键,主键索引就是聚集索引。
如果不存在主键,将使用第一个唯一(UNIQUE)索引作为聚集索引。
如果表没有主键,或没有合适的唯一索引,则InnoDB会自动生成一个 rowid作为隐藏的聚集索引。
非聚族索引(二级索引)值的是数据与索引分开存储,B+树的叶子节点保存对应的主键,可以有多个,一般我们自定义的索引都是非聚簇索引
知道什么是回表查询嘛?
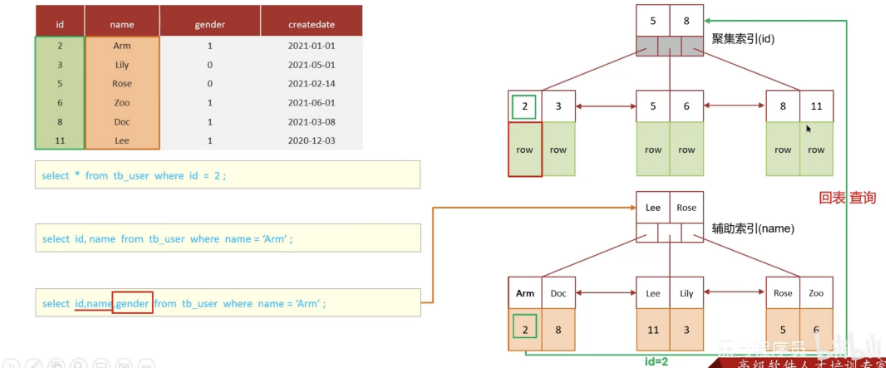
嗯,其实跟刚才介绍的聚簇索引和非聚簇索引是有关系的,回表的意思就是通过二级索引找到对应的主键值,然后再通过主键值找到聚集索引中所对应的整行数据,这个过程就是回表
知道什么叫覆盖索引嘛?
覆盖索引是指 select查询语句使用了索引,在返回的数据列,必须在索引中全部能够找到,如果我们使用 id查询,它会直接走聚集索引查询,一次索引扫描,直接返回数据,性能高。如果按照二级索引查询数据的时候,返回的列中没有创建索引,有可能会触发回表查询,尽量避免使用 select*,尽量在返回的列中都包含添加索引的字段
MYSQL超大分页怎么处理?
超大分页一般都是在数据量比较大时,我们使用了 limit分页查询,并且需要对数据进行排序,这个时候效率就很低,我们可以采用覆盖索引和子查询来解决。先分页查询数据的 id字段,确定了 id之后,再用子查询来过滤,只查询这个 id列表中的数据就可以了因为查询 id的时候,走的覆盖索引,所以效率可以提升很多
select*
from tb sku t.
(select id from tb sku order by id limit 9000000,10) a
where t. id = a. id;索引创建原则有哪些?
1).针对于数据量较大,且查询比较频繁的表建立索引。单表超过10万数据(增加用户体验)
2).针对于常作为查询条件(where)、排序 (order by)、分组 (group by) 操作的字段建立索引。
3).尽量选择区分度高的列作为索引,尽量建立唯一索引,区分度越高,使用索引的效率越高,建立联合索引时,要把区分度大的字段排在前面,这样区分度大的字段越有可能被更多的 SQL 使用到。
4).如果是字符串类型的字段,字段的长度较长,可以针对于字段的特点,建立前缀索引。
5).尽量使用联合索引,减少单列索引,查询时,联合索引很多时候可以覆盖索引,节省存储空间,避免回表,提高查询效率。
6).要控制索引的数量,索引并不是多多益善,索引越多,维护索引结构的代价也就越大,会影响增删改的效率。
7).如果索引列不能存储NULL值,请在创建表时使用NOT NULL约束它。当优化器知道每列是否包含NULL值时,它可以更好地确定哪个索引最有效地用于查询。
什么情况下索引会失效
1.使用联合索引时违反最左前缀法则
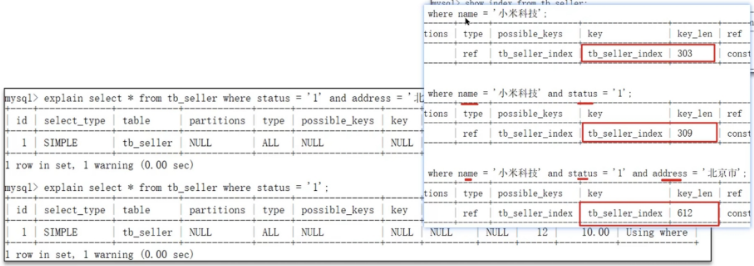
如果符合最左法则,但是出现跳跃某一列,只有最左列索引生效:

2.使用联合索引时范围查询右边的列,不能使用索引。
根据前面的两个字段name, status查询是走索引的,但是最后一个条件address没有用到索引。

3.在索引列上进行函数运算操作,造成索引失效
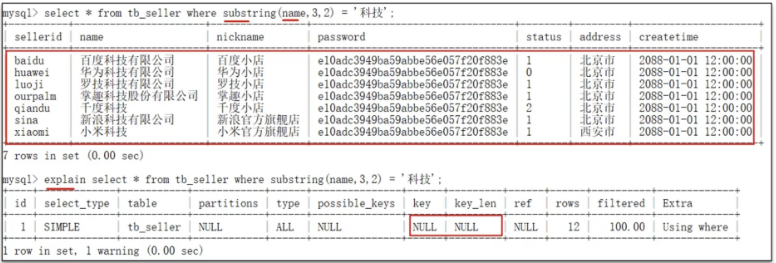
4.查询字段发生类型转换,比如字符串不加单引号,造成索引失效

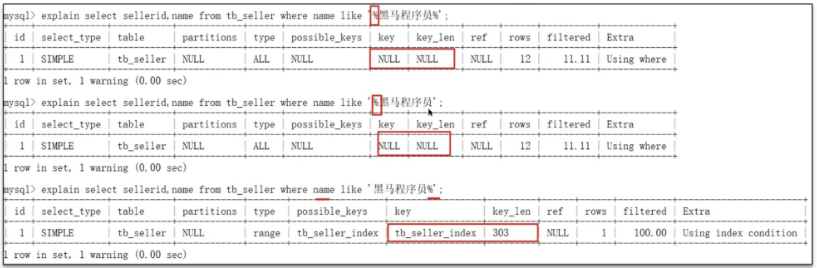
5.以%开头的Like模糊查询,索引失效。如果仅仅是尾部模糊匹配,索引不会失效。如果是头部模糊匹配,索引失效。
谈谈你对sql的优化的经验
1.定位慢SQL:
开启MySQL慢查询日志(slow_query_log=ON),设置阈值(long_query_time=1);
使用SHOW PROCESSLIST查看当前执行的SQL;
监控工具(如Prometheus+Grafana、Percona Monitoring Tools)。
2.分析执行计划:
使用EXPLAIN <SQL>查看执行计划,关注以下字段:
type:访问类型(ALL全表扫描→index索引扫描→range范围查询→ref索引相等查询→eq_ref主键/唯一索引查询→system表只有一行);
key:使用的索引;
rows:扫描行数;
Extra:额外信息(Using filesort需排序→Using temporary需临时表→Using index覆盖索引)。
3.优化策略:
表结构优化:
为WHERE、ORDER BY、GROUP BY字段添加索引;
使用复合索引(遵循最左前缀原则)。
避免索引失效(如LIKE '%abc'、函数操作、类型转换、OR条件);
分库分表(数据量过大时)。
比如设置合适的数值 (tinyint int bigint) , 要根据实际情况选择,(如INT代替VARCHAR存储数字)
比如设置合适的字符串类型 (char和varchar) char定长效率高, varchar可变长度,效率稍低
SQL语句优化:
避免SELECT *,SELECT语句务必指明字段名称,避免直接使用select*(避免回表查询);
SQL语句要避免造成索引失效的写法
避免在where子句中对字段使用函数进行表达式操作
尽量用union all代替union,union会多一次过滤,效率低
Join优化能用inner join就不用left join right join,如必须使用一定要以小表为驱动,内连接会对两个表进行优化,优先把小表放到外边,把大表放到里边。left join或right join,不会重新调整顺序
避免子查询(改为JOIN或EXISTS);
批量操作(如INSERT INTO ... VALUES (...), (...)代替多次单条插入);
限制返回行数(LIMIT)。
MySQL为什么InnoDB是默认引擎?
InnoDB引擎在事务支持、并发性能、崩溃恢复等方面具有优势,因此被MySQL选择为默认的存储引擎。
事务支持:InnoDB引擎提供了对事务的支持,可以进行ACID(原子性、一致性、隔离性、持久性)属性的操作。Myisam引擎不支持事务。
并发性能:InnoDB引擎采用了行级锁定的机制,可以提供更好的并发性能,Myisam存储引擎只支持表锁,锁的粒度比较大。
崩溃恢复:InnoDB引引擎通过 redolog 日志实现了崩溃恢复,可以在数据库发生异常情况(如断电)时,通过日志文件进行恢复,保证数据的持久性和一致性。Myisam是不支持崩溃恢复的。
事务的特性是什么?可以详细说一下吗?
ACID,分别指的是:原子性、一致性、隔离性、持久性;
我举个例子:A向B转账500,转账成功,A扣除500元,B增加500元。原子性操作体现在要么都成功,要么都失败;在转账的过程中,数据要有一致性,A扣除了500,B必须增加500,操作前后总数是一致的;在转账的过程中,隔离性体现在A像B转账,不能受其他事务干扰;在转账的过程中,持久性体现在事务提交后,要把数据持久化(可以说是落盘操作)
事务隔离级别
事务隔离级别越高,数据越安全,但是性能越低。
串行化隔离级别是通过什么实现的?
是通过行级锁来实现的,序列化隔离级别下,普通的 select 查询是会对记录加 S 型的 next-key 锁,其他事务就没没办法对这些已经加锁的记录进行增删改操作了,从而避免了脏读、不可重复读和幻读现象。
一条update是不是原子性的?为什么?
是原子性,主要通过锁+undolog 日志保证原子性的
执行 update 的时候,会加行级别锁,保证了一个事务更新一条记录的时候,不会被其他事务干扰。 事务执行过程中,会生成 undolog,如果事务执行失败,就可以通过 undolog 日志进行回滚。
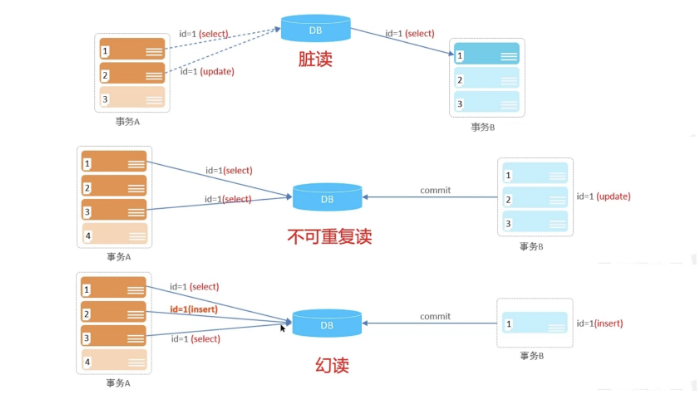
并发事务问题
脏读: 一个事务读到另外一个事务还没有提交的数据。
不可重复读:一个事务先后读取同一条记录,但两次读取的数据不同,称之为不可重复读。
幻读: 一个事务按照条件查询数据时,没有对应的数据行,但是在插入数据时,又发现这行数据已经存在,好像出现了”幻影”。
日志文件是分成了哪几种?
redo log 重做日志,是 Innodb 存储引擎层生成的日志,实现了事务中的持久性,主要用于掉电等故障恢复;
undo log 回滚日志,是 Innodb 存储引擎层生成的日志,实现了事务中的原子性,主要用于事务回滚和 MVCC。
bin log 二进制日志,是 Server 层生成的日志,主要用于数据备份和主从复制;
relay log 中继日志,用于主从复制场景下,slave通过io线程拷贝master的bin log后本地生成的日志 慢查询日志,用于记录执行时间过长的sql,需要设置阈值后手动开启
undo log和redo log的区别
● redo log:记录的是数据页的物理变化,服务宕机可用来同步数据
● undo log:记录的是逻辑日志,当事务回滚时,通过逆操作恢复原来的数据
● redo log保证了事务的持久性,undo log保证了事务的原子性和一致性
好的,事务中的隔离性是如何保证的呢?
排他锁(如一个事务获取了一个数据行的排他锁,其他事务就不能再获取该行的其他锁)
mvcc:多版本并发控制
你解释一下MVCC
MySQL中的多版本并发控制。指维护一个数据的多个版本,使得读写操作没有冲突
隐藏字段:
① trx _ id(事务id),记录每一次操作的事务id,是自增的
② roll _ pointer(回滚指针),指向上一个版本的事务版本记录地址
undo log:
①回滚日志,存储老版本数据
②版本链:多个事务并行操作某一行记录,记录不同事务修改数据的版本,通过roll _ pointer指针形成一个链表
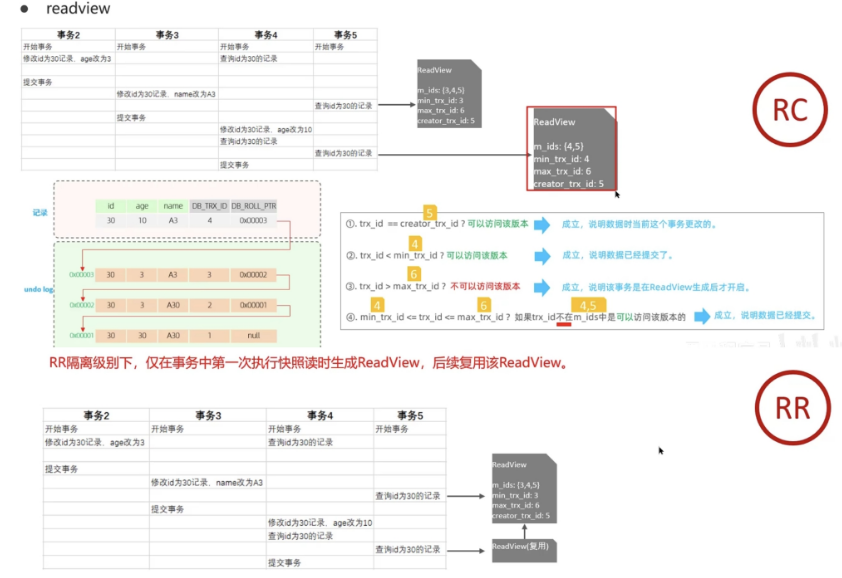
readView读视图解决的是一个事务查询选择版本的问题
根据readView的匹配规则和当前的一些事务id判断该访问那个版本的数据,不同的隔离级别快照读是不一样的,最终的访问的结果不一样
RC:每一次执行快照读时生成ReadView
RR:仅在事务中第一次执行快照读时生成ReadView,后续复用
说一下主从同步的原理?
MySQL主从复制的核心就是二进制日志,二进制日志记录了所有的DDL语句和DML语句具体的主从同步过程大概的流程是这样的:
1. Master主库在事务提交时,会把数据变更记录在二进制日志文件Binlog中。
2.从库读取主库的二进制日志文件Binlog,写入到从库的中继日志Relay Log.
3. slave重做中继日志中的事件,将改变反映它自己的数据。
你们项目用过分库分表吗
业务介绍
1,根据自己简历上的项目,想一个数据量较大业务(请求数多或业务累积大)
2,达到了什么样的量级(单表1000万或超过20G)
具体拆分策略
1,水平分库,将一个库的数据拆分到多个库中,解决海量数据存储和高并发的问题
2,水平分表,解决单表存储和性能的问题
3,垂直分库,根据业务进行拆分,高并发下提高磁盘IO和网络连接数
4,垂直分表,冷热数据分离,多表互不影响





